
20 Inference about Categorical Data
In the previous chapter, we talk about the one-sample and two-sample proportion tests, testing either the proportion of some category is equal to, greater than, or less than some value, or whether or not the two proportions of the same category from the two groups are equal, or which one is larger. The idea starts from the binomial distribution where the categorical variable being studied has only two possible categories.
In our daily lives, there are lots of categorical variables that have more than two categories, for example, car brands, eye colors, etc. In this chapter, we are going to learn two specific tests: test of goodness-of-fit and test of independence that generally consider more than two categories and the associated proportions.
Categorical Variable with More Than 2 Categories
Suppose a categorical variable has \(k\) categories \(A_1, \dots, A_k\), \(k \ge 2\). For example, we may want to know the eye color distribution of Marquette students. We can have \(A_1 = black\), \(A_2 = brown\), \(A_3 = blue\), \(A_4 = green\), and our data set may be like
| Subject | \(A_1\) | \(A_2\) | \(\cdots\) | \(\cdots\) | \(A_k\) |
|---|---|---|---|---|---|
| 1 | x | ||||
| 2 | x | ||||
| 3 | x | ||||
| \(\vdots\) | |||||
| \(n\) | x |
So the first guy has black eyes, and the second one has blown eyes, and so on.
With the size \(n\), for categories \(A_1, \dots , A_k\), their observed count is \(O_1, \dots, O_k\), and \(\sum_{i=1}^kO_i = n\). The count information can be summarized in the one-way count/frequency table:
| \(A_1\) | \(A_2\) | \(\cdots\) | \(A_k\) | Total |
|---|---|---|---|---|
| \(O_1\) | \(O_2\) | \(\cdots\) | \(O_k\) | \(n\) |
For example, if we have \(n = 100\) students, and 30 have black eyes, 35 have brown eyes, 20 have blue eyes, and 15 have green eyes, then \(O_1 = 30\), \(O_2 = 35\), \(O_3 = 20\), and \(O_4 = 15\). This is the sample data, and we have the sample proportion for each category, \(\hat{\pi}_i =O_i/n\), \(i = 1, \dots, k.\) In the example, \(\hat{\pi}_1 = 0.3\), \(\hat{\pi}_2 = 0.35\),\(\hat{\pi}_3 = 0.2\), and \(\hat{\pi}_4 = 0.15\).
Of course this is not the true proportion or distribution of eye colors, and our goal is to test whether or not the observed distribution follows some hypothesized distribution, for example the eye color distribution of all Americans. Also, we may be interested in whether or not the distributions from the two groups are more or less the same. For example, the eye color distribution of male and female students.
Note
- The count of categories of a categorical variable having more than two categories is associated with the multinomial distribution. The binomial distribution is a special case of the multinomial distribution when \(k = 2\).
- Here we use \(O_i\) to represent the observed count of category \(A_i\). It works the same as the \(y\) in the previous binomial case. We stick with \(O_i\) notations in order to be consistent with most of other statistics books.
20.1 Test of Goodness of Fit
A citizen in Wauwatosa, WI is curious about the question:
Are the selected jurors racially representative of the population?
Well the idea is that if the jury is representative of the population, once we collect our sample of juries, the sample proportions should reflect the proportions of the population of eligible jurors (i.e. registered voters).
Suppose from the government we learn the distribution of registered voters based on races. We then collect 275 jurors racial information, and see if the racial distribution of the sample is kind of consistent with the registered voter racial distribution. The count information is summarized in the table below.
| White | Black | Hispanic | Asian | Total | |
|---|---|---|---|---|---|
| Representation in juries | 205 | 26 | 25 | 19 | 275 |
| Registered voters | 0.72 | 0.07 | 0.12 | 0.09 | 1.00 |
The first thing we can do is convert the count into proportion or relative frequency, so that the sample proportion and the target proportion can be easily paired and compared.
| White | Black | Hispanic | Asian | Total | |
|---|---|---|---|---|---|
| Representation in juries | 0.745 | 0.095 | 0.091 | 0.069 | 1.00 |
| Registered voters | 0.72 | 0.07 | 0.12 | 0.09 | 1.00 |
While the proportions in the juries do not precisely represent the population proportions, it is unclear whether these data provide convincing evidence that the sample is not representative. If the jurors really were randomly sampled from the registered voters, we might expect small differences due to chance. However, unusually large differences may provide convincing evidence that the juries were not representative. Specifically, we want a test to answer the question
Are the proportions of juries close enough to the proportions of registered voters, so that we are confident saying that the jurors really were randomly sampled from the registered voters?
Note
As the binomial case, the multi-class counts \(O_1, O_2 \dots O_k\) and proportions \(O_1/n, O_2/n \dots O_k/n\) are random variables before actual data are collected. Their value varies from sample to sample.
The test we need is the goodness-of-fit test.
Goodness-of-Fit Test
A goodness-of-fit test tests the hypothesis that the observed frequency distribution fits or conforms to some claim distribution. In the jury example, our observed (relative) frequency distribution is \((0.745, 0.095, 0.091, 0.069)\) and the claim distribution is the racial distribution of registered voters \((0.72, 0.07, 0.12, 0.09)\). The jury representatives work as our sample, and the registered voters is the population. We wonder if the sample is representative of the general population. If yes, the sample should looks like the population, and sample distribution should conform to the population distribution.
Here is the question: “If the individuals are randomly selected to serve on a jury, about how many of the 275 people would we expect to be white? How about black?” We ask this question because we want to know how the jury distribution looks like if the distribution does follow the distribution of the registered voters. If what we expect to see is far from what we observe, then the jury is probably not randomly sampled from the registered voters. This matches our testing rationale. We do the testing under the null hypothesis, the scenario that the observed frequency distribution fits or conforms to some claim distribution.
| White | Black | Hispanic | Asian | |
|---|---|---|---|---|
| Registered voters | 0.72 | 0.07 | 0.12 | 0.09 |
According to the claimed distribution, \(72\%\) of the population is white, so we would expect about \(72\%\) of the jurors to be white. In other words, we expect to see \(0.72 \times 275 = 198\) white jurors in the sample of 275 jury members. We expect about \(7\%\) of the jurors to be black. This corresponds to about \(0.07 \times 275 = 19.25\) black jurors in the sample. The table below shows the observed count and the expected count if members are randomly selected for each ethnic group. In general, the expected count of a category is the total count times the proportion or probability of the category.
| White | Black | Hispanic | Asian | Total | |
|---|---|---|---|---|---|
| Observed Count \(O_i\) | 205 | 26 | 25 | 19 | 275 |
| Expected Count \(E_i\) | 198 | 19.25 | 33 | 24.75 | 275 |
| Population Proportion \((H_0)\) | 0.72 | 0.07 | 0.12 | 0.09 | 1.00 |
While some sampling variation is expected, the observed count and expected count should be similar if there was no bias in selecting the members of the jury. But how similar is similar enough? We want to test whether the differences are strong enough to provide convincing evidence that the jurors were not selected from a random sample of all registered voters.
Goodness-of-Fit Test Example
Before we introduce the test procedure, to have better performance the goodness-of-fit test requires each expected count is as least five. The higher the better.
In words, our hypotheses are \[\begin{align} &H_0: \text{No racial bias in who serves on a jury, and } \\ &H_1: \text{There is racial bias in juror selection} \end{align}\]
If the true racial distribution of juries is \((\pi_1, \pi_2, \pi_3, \pi_4)\), where
- \(\pi_1\) is the proportion of White in jury
- \(\pi_2\) is the proportion of Black in jury
- \(\pi_3\) is the proportion of Hispanic in jury
- \(\pi_4\) is the proportion of Asian in jury
we want to know if the distribution conforms to the claim racial distribution of register voters \((\pi_1^0, \pi_2^0, \pi_3^0, \pi_4^0) = (0.72, 0.07, 0.12, 0.09)\) where
- \(\pi_1^0\) is the proportion of White in register voters
- \(\pi_2^0\) is the proportion of Black in register voters
- \(\pi_3^0\) is the proportion of Hispanic in register voters
- \(\pi_4^0\) is the proportion of Asian in register voters
In general, we can rewrite our hypotheses in mathematical notations: \[\begin{align} &H_0: \pi_1 = \pi_1^0, \pi_2 = \pi_2^0, \dots, \pi_k = \pi_k^0\\ &H_1: \pi_i \ne \pi_i^0 \text{ for some } i \end{align}\]
Note that \(H_1\) is not \(\pi_i \ne \pi_i^0 \text{ for all } i\). As long as one \(\pi_i \ne \pi_i^0\) holds, the \(H_0\) statement is not true.
The test statistic is a chi-squared statistic from the chi-squared distribution with degrees of freedom \(k-1\). Under \(H_0\), the test statistic is
\[\chi^2_{test} = \frac{(O_1 - E_1)^2}{E_1} + \frac{(O_2 - E_2)^2}{E_2} + \cdots + \frac{(O_k - E_k)^2}{E_k},\] where \(O_i\) is the observed count of the \(i\)-th category, and \(E_i = n\pi_i^0\) is the expected count of the \(i\)-th category, \(i = 1, \dots, k.\)
The goodness-of-fit test is a chi-squared test that is always right-tailed. So we reject \(H_0\) if \(\chi^2_{test} > \chi^2_{\alpha, k-1}\). Look at the test statistic formula carefully. When will the test statistic be large or the evidence be strong? The numerator term \((O_i-E_i)^2\) is the squared distance between the observed and expected counts. When the two are farther away from each other, the test statistic or evidence will be stronger. As a result, when the observed count distribution is more inconsistent with the distribution we expect to see, it is more likely to conclude that the sample is not randomly drawn from the claim or assumed population distribution.
Back to our example.
| White | Black | Hispanic | Asian | |
|---|---|---|---|---|
| Observed Count | \(O_1 = 205\) | \(O_2 = 26\) | \(O_3 = 25\) | \(O_4 = 19\) |
| Expected Count | \(E_1 = 198\) | \(E_2 = 19.25\) | \(E_3 = 33\) | \(E_4 = 24.75\) |
| Proportion under \(H_0\) | \(\pi_1^0 = 0.72\) | \(\pi_2^0 = 0.07\) | \(\pi_3^0 = 0.12\) | \(\pi_4^0 = 0.09\) |
Under \(H_0\), \(\chi^2_{test} = \frac{(205 - 198)^2}{198} + \frac{(26 - 19.25)^2}{19.25} + \frac{(25 - 33)^2}{33} + \frac{(19 - 24.75)^2}{24.75} = 5.89\).
With \(\alpha = 0.05\), \(\chi^2_{0.05, 3} = 7.81\). Because \(5.89 < 7.81\), we fail to reject \(H_0\) in favor of \(H_1\). Therefore, we do not have convincing evidence of racial bias in the juror selection process.
Below is an example of how to perform a goodness-of-fit test in R. Because the goodness-of-fit test is a chi-squared test, we use the function chisq.test(). The argument x is the observed count vector of length \(k\), and the argument p is the hypothesized proportion distribution which is a vector of probabilities of the same length as x. The function does not provide the critical value, but it gives us the \(p\)-value. Since the \(p\)-value is greater than \(0.05\), we do not reject \(H_0\).
obs <- c(205, 26, 25, 19)
pi_0 <- c(0.72, 0.07, 0.12, 0.09)
## Use chisq.test() function
chisq.test(x = obs, p = pi_0)
Chi-squared test for given probabilities
data: obs
X-squared = 5.8896, df = 3, p-value = 0.1171
Note
The chi-squared test can be used in two-sided one-sample proportion test. Suppose we are doing the following test
\[\begin{align} &H_0: \pi_1 = 0.5, \pi_2 = 0.5 \\ &H_1: \pi_i \ne 0.5 \text{ for some } i \end{align}\]
Because there are only two categories, we automatically know the value of \(\pi_2\) when we know the value of \(\pi_1\) as \(\pi_2 = 1 - \pi_1\). So the hypothesis can be reduced to
\[\begin{align} &H_0: \pi_1 = 0.5 \\ &H_1: \pi_1 \ne 0.5 \end{align}\] or even
\[\begin{align} &H_0: \pi = 0.5 \\ &H_1: \pi \ne 0.5 \end{align}\] when we use \(\pi\) for the proportion of the first category and \(1-\pi\) for the second. We just transform a chi-squared test setting into a two-sided one-sample proportion test setting!
Suppose \(n = 1000\), \(O_1 = 520\), \(O_2 = 480\), \(\pi_1^0 = \pi_2^0 = 0.5\). Our chi-squared test is
chisq.test(x = c(520, 480), p = c(0.5, 0.5))
Chi-squared test for given probabilities
data: c(520, 480)
X-squared = 1.6, df = 1, p-value = 0.2059In the language of the one-sample proportion test, we have \(n = 1000\), \(y = 520\), \(\pi^0 = 0.5\). \((y = O_1 = 520, n-y = O_2 = 480)\)
prop.test(x = 520, n = 1000, p = 0.5, alternative = "two.sided",
correct = FALSE)
1-sample proportions test without continuity correction
data: 520 out of 1000, null probability 0.5
X-squared = 1.6, df = 1, p-value = 0.2059
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.4890177 0.5508292
sample estimates:
p
0.52 Do you see the two tests are equivalent? They have the same test statistic, degrees of freedom as well as \(p\)-value. Both lead to the same conclusion.
Below is an example of how to perform a goodness-of-fit test in Python. Because the goodness-of-fit test is a chi-squared test, we use the function chisquare() in scipy.stats. The argument f_obs is the observed count vector of length \(k\), and the argument f_exp is the hypothesized or expected number of observations if the proportion distribution follows the hypothesized or expected proportions. The function does not provide the critical value, but it gives us the \(p\)-value. Since the \(p\)-value is greater than \(0.05\), we do not reject \(H_0\).
from scipy.stats import chisquare# Observed frequencies
obs = [205, 26, 25, 19]
# Expected proportions
pi_0 = [0.72, 0.07, 0.12, 0.09]
# Convert expected proportions to expected frequencies
expected = [p * sum(obs) for p in pi_0]
# Chi-square goodness-of-fit test
chisquare(f_obs=obs, f_exp=expected)Power_divergenceResult(statistic=5.889610389610387, pvalue=0.11710619130850633)
Note
The chi-squared test can be used in two-sided one-sample proportion test. Suppose we are doing the following test
\[\begin{align} &H_0: \pi_1 = 0.5, \pi_2 = 0.5 \\ &H_1: \pi_i \ne 0.5 \text{ for some } i \end{align}\]
Because there are only two categories, we automatically know the value of \(\pi_2\) when we know the value of \(\pi_1\) as \(\pi_2 = 1 - \pi_1\). So the hypothesis can be reduced to
\[\begin{align} &H_0: \pi_1 = 0.5 \\ &H_1: \pi_1 \ne 0.5 \end{align}\] or even
\[\begin{align} &H_0: \pi = 0.5 \\ &H_1: \pi \ne 0.5 \end{align}\] when we use \(\pi\) for the proportion of the first category and \(1-\pi\) for the second. We just transform a chi-squared test setting into a two-sided one-sample proportion test setting!
Suppose \(n = 1000\), \(O_1 = 520\), \(O_2 = 480\), \(\pi_1^0 = \pi_2^0 = 0.5\). Our chi-squared test is
# Observed frequencies
obs = [520, 480]
# Expected proportions
expected = [0.5, 0.5]
# Convert expected proportions to expected frequencies
expected_freq = [p * sum(obs) for p in expected]
# Chi-square test
chisq_test_res = chisquare(f_obs=obs, f_exp=expected_freq)
chisq_test_resPower_divergenceResult(statistic=1.6, pvalue=0.20590321073206466)In the language of the one-sample proportion test, we have \(n = 1000\), \(y = 520\), \(\pi^0 = 0.5\). \((y = O_1 = 520, n-y = O_2 = 480)\)
from statsmodels.stats.proportion import proportions_ztest, proportion_confint
z_test_stat, pval = proportions_ztest(count=520, nobs=1000, value=0.5,
alternative='two-sided')
pval 0.2055402182226186proportion_confint(count=520, nobs=1000, alpha=0.05, method='normal')(0.48903505011072596, 0.5509649498892741)Do you see the two tests are equivalent? If you look at the proportion test output carefully, you’ll find that the square of the \(z\) statistic is equal to the chi-squared statistic with degrees of freedom one, i.e., \(z_{test}^2 = \chi^2_{1, test}\), and the \(z\) test here is equivalent to the chi-squared test for two-sided tests.
z_test_stat1.2659242088545843z_test_stat ** 21.6025641025641053chisq_test_res.statistic1.6Both lead to the same conclusion.
20.2 Test of Independence
So far we consider one categorical variable with general \(k\) categories. In some situations, we have two categorical variables being considered, and we wonder if one affects the other distribution. Formally, we want to test whether or not the two variables are independent each other. The test doing this is the independence test.
Contingency Table and Expected Count
Contingency Table
Let’s start with an example. A popular question in politics is “Does the opinion of the President’s job performance depend on gender?” This question may involve two categorical variables such as
Job performance: approve, disapprove, no opinion
Gender: male, female
To answer such question, as every other test, we collect our data and see if there is any sufficient evidence to say the two variables are dependent. When two categorical variables are involved, we usually summarize the data in a contingency table or two-way frequency/count table as shown below.
| Approve | Disapprove | No Opinion | Total | ||
|---|---|---|---|---|---|
| Male | 18 | 22 | 10 | 50 | |
| Female | 23 | 20 | 12 | 55 | |
| Total | 41 | 42 | 22 | 105 |
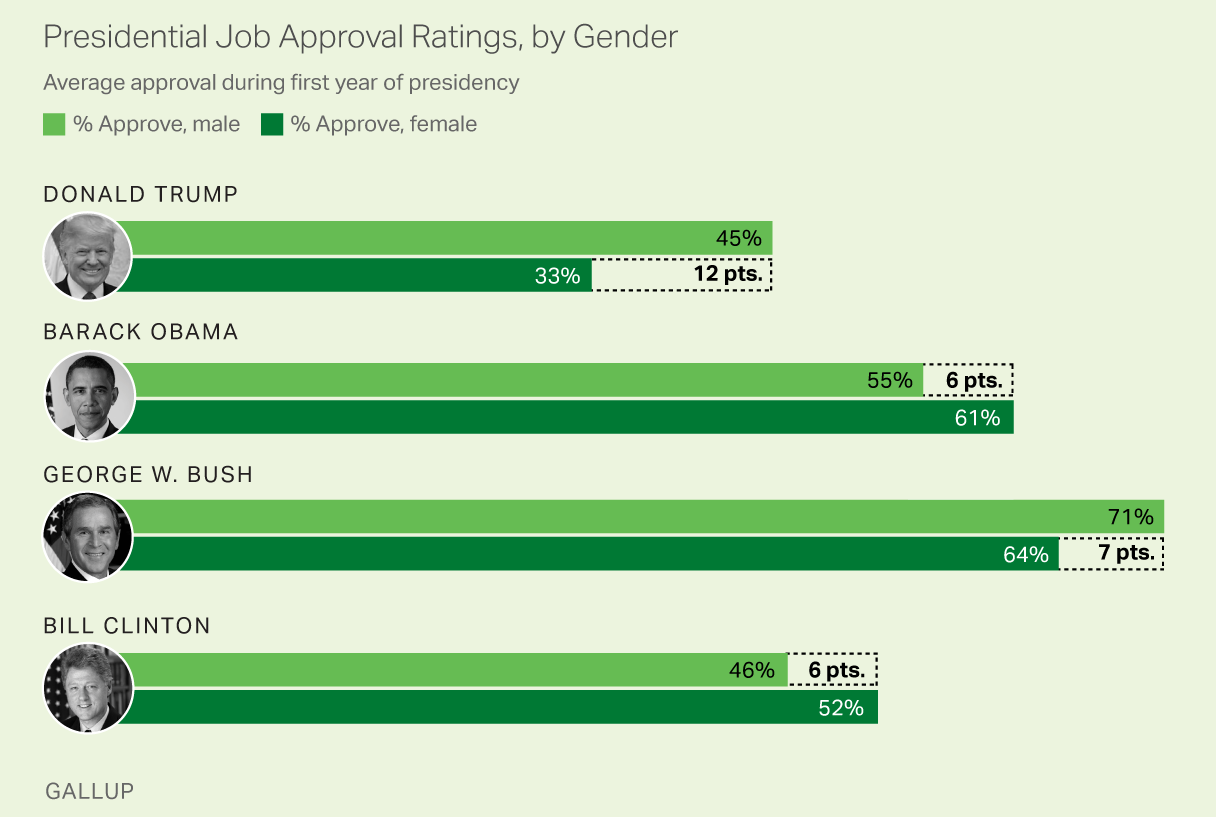
When we consider a two-way table, we often would like to know, are these variables related in any way? That is, are they dependent (versus independent)? If President’s approval rate has nothing to do with gender, the Job performance distributions in the male and female groups should be similar or consistent. In other words, whether or not the person is male or female does not affect how President’s job performance is viewed.
Expected Count
The idea is similar to goodness-of-fit test. We first calculate the expected count in each cell (Total row and column are excluded) in the contingency table, the count we expect to see under the condition that the two variables are independent. We always do our analysis in the world of null hypothesis that two variables have no relationship.
| Approve | Disapprove | No Opinion | Total | |
|---|---|---|---|---|
| Male | 18 (19.52) | 22 (20) | 10 (10.48) | 50 |
| Female | 23 (21.48) | 20 (22) | 12 (11.52) | 55 |
| Total | 41 | 42 | 22 | 105 |
The expected count for the \(i\)-th row and \(j\)-th column, which is listed in parentheses in the table above, is calculated by: \[\text{Expected Count}_{\text{row i; col j}} = \frac{\text{(row i total}) \times (\text{col j total})}{\text{table total}}\] For example, the expected count of Disapprove in the Female group is \[\text{Expected Count}_{\text{row 2; col 2}} = \frac{\text{(row 2 total}) \times (\text{col 2 total})}{\text{table total}} = \frac{42 \times 55}{105} = 22.\]
We are ready for doing test of independence once all expected counts are obtained.
Test of Independence Procedure
The test of independence requires that every expected count \(E_{ij} \ge 5\) in the contingency table. The higher the better.
As we discussed before, we believe the variables are independent unless strong evidence says they are not. So our hypotheses are \[\begin{align} &H_0: \text{Two variables are independent }\\ &H_1: \text{The two are dependent (associated) } \end{align}\]
The test statistic formula is pretty similar to the test of goodness-of-fit. The test of independence is also a chi-squared test. The chi-squared test statistic is
\[\chi^2_{test} = \sum_{i=1}^r\sum_{j=1}^c\frac{(O_{ij} - E_{ij})^2}{E_{ij}},\] where \(r\) is the number of rows and \(c\) is the number of columns in the contingency table. The idea is the same as the test of goodness-of-fit. Under the assumption of independence, if the observed counts are far away from the counts we should expect to see, we get a larger test statistic, and tend to conclude that the independence assumption is not reasonable.
The chi-squared test is right-tailed, so we reject \(H_0\) if \(\chi^2_{test} > \chi^2_{\alpha, \, df}\), where \(df = (r-1)(c-1)\).
Example
| Approve | Disapprove | No Opinion | Total | |
|---|---|---|---|---|
| Male | 18 (19.52) | 22 (20) | 10 (10.48) | 50 |
| Female | 23 (21.48) | 20 (22) | 12 (11.52) | 55 |
| Total | 41 | 42 | 22 | 105 |
\[\begin{align} &H_0: \text{ Opinion does not depend on gender } \\ &H_1: \text{ Opinion and gender are dependent } \end{align}\]
The test statistic is \[\small \chi^2_{test} = \frac{(18 - 19.52)^2}{19.52} + \frac{(22 - 20)^2}{20} + \frac{(10 - 10.48)^2}{10.48} + \frac{(23 - 21.48)^2}{21.48} + \frac{(20 - 22)^2}{22} + \frac{(12 - 11.52)^2}{11.52}= 0.65\]
The critical value is \(\chi^2_{\alpha, df} =\chi^2_{0.05, (2-1)(3-1)} = 5.991\). Since \(\chi_{test}^2 < \chi^2_{\alpha, df}\), we do not reject \(H_0\). Therefore we fail to conclude that the opinion of the President’s job performance depends on gender.
Calculating all the expected counts is tedious, especially when the variables have many categories. In practice we never calculate them by hand, and use computing software to do so.
Below is an example of how to perform the test of independence using R. Since the test of independence is a chi-squared test, we still use the chisq.test() function. This time we need to prepare the contingency table as a matrix, and put the matrix in the x argument in the function. That’s it! R does everything for us. If we save the result as an object like ind_test which is a R list, we can get access to information related to the test, such as the expected counts ind_test$expected.
[,1] [,2] [,3]
[1,] 18 22 10
[2,] 23 20 12## Using chisq.test() function
(ind_test <- chisq.test(x = contingency_table))
Pearson's Chi-squared test
data: contingency_table
X-squared = 0.65019, df = 2, p-value = 0.7225## extract expected counts
ind_test$expected [,1] [,2] [,3]
[1,] 19.52381 20 10.47619
[2,] 21.47619 22 11.52381## critical value
qchisq(0.05, df = (2 - 1) * (3 - 1), lower.tail = FALSE) [1] 5.991465Below is an example of how to perform the test of independence using Python. The function we use is chi2_contingency() in scipy.stats since the test of independence relies on a contingency table. We first prepare the contingency table as a matrix, and put the matrix in the observed argument in the function. That’s it! Python does everything for us. If we save the result as an object like ind_test, we can get access to information related to the test, such as the expected counts ind_test.expected_freq.
import numpy as np
from scipy.stats import chi2_contingency, chi2
contingency_table = np.array([[18, 22, 10], [23, 20, 12]])
contingency_tablearray([[18, 22, 10],
[23, 20, 12]])# Chi-square test of independence
ind_test = chi2_contingency(observed=contingency_table)
ind_test.statistic0.6501914936504742ind_test.pvalue0.7224581772535765ind_test.dof2ind_test.expected_freqarray([[19.52380952, 20. , 10.47619048],
[21.47619048, 22. , 11.52380952]])# Critical value for chi-square distribution
chi2.ppf(0.95, df=(2-1)*(3-1))5.99146454710797920.3 Test of Homogeneity
Test of homogeneity is a generalization of the two-sample proportion test. This test determines if two or more populations (or subgroups of a population) have the same distribution of a single categorical variable having two or more categories.
More to be added.
20.4 Exercises
- A researcher has developed a model for predicting eye color. After examining a random sample of parents, she predicts the eye color of the first child. The table below lists the eye colors of offspring. On the basis of her theory, she predicted that 87% of the offspring would have brown eyes, 8% would have blue eyes, and 5% would have green eyes. Use 0.05 significance level to test the claim that the actual frequencies correspond to her predicted distribution.
| Eye Color | Brown | Blue | Green |
| Frequency | 127 | 21 | 5 |
- In a study of high school students at least 16 years of age, researchers obtained survey results summarized in the accompanying table. Use a 0.05 significance level to test the claim of independence between texting while driving and driving when drinking alcohol. Are these two risky behaviors independent of one another?
| Drove after drinking alcohol? | ||
|---|---|---|
| Yes | No | |
| Texted while driving | 720 | 3027 |
| Did not text while driving | 145 | 4472 |